Memcached
- Memcached是一个免费开源、高性能的分布式内存对象缓存系统,通过减少数据库加载来加速动态的web应用。
- Memcached是一个内存中的存储键值对的HashMap,可以使用key-value存储任意的数据,数据比如来自数据库调用、API调用、页面渲染等的结果,类型是字符串、对象。
- Libmemcached是一个开源的Memcached客户端库,其内部实现了分布式管理、内存池等功能。通过API的形式提供出来,使用程序员可以专心上层业务逻辑,避免底层与memcached交互的细节。
1. 组成
- Client software, which is given a list of available memcached servers.
- A client-based hashing algorithm, which chooses a server based on the “key”.
- Server software, which stores values with their keys into an internal hash table.
- LRU, which determine when to throw out old data (if out of memory), or reuse memory.
2. 设计原理
2.1 Simple Key/Value Store
- Data: Items are made up of a key, an expiration time, optional flags, and raw data(原始数据).
- Must upload data that is pre-serialized
2.2 Logic Half in Client, Half in Server
- Clients understand how to choose which server to read or write to for an item, what to do when it cannot contact a server.
- The servers understand how to store and fetch items. Also manage when to evict or reuse memory.
2.3 Servers are Disconnected From Each Other
- Memcached servers are unaware of each other.
- Adding servers increases the available memory.
- Cache invalidation → clients delete or overwrite the data, clients directly address the server holding the data to be invalidated.
2.4 O(1)
2.5 Forgetting is a Feature
- a Least Recently Used cache.
- Expire items after a minute to limit stale data being returned, or flush unused data in an effort to retain frequently requested information.
3. Memcached访问模式
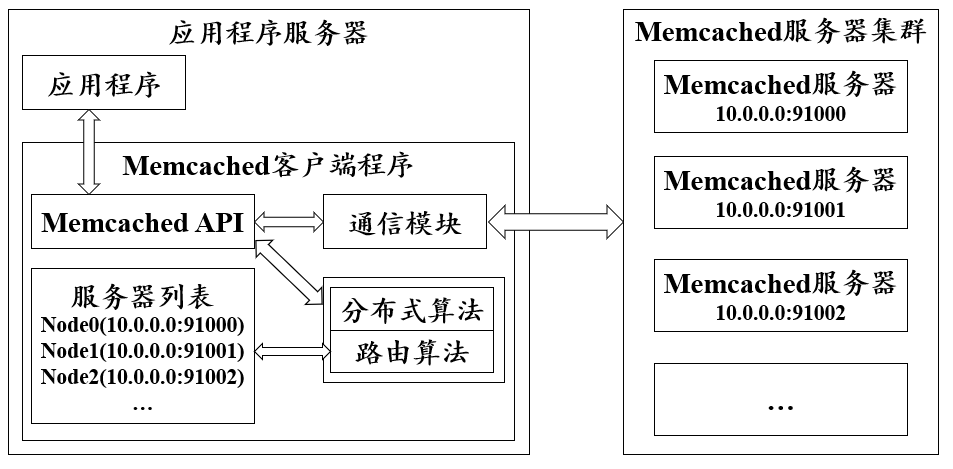
MemCache虽然被称为”分布式缓存”,但是MemCache本身完全不具备分布式的功能,MemCache集群的节点之间不会相互通信,如何”分布式”,完全依赖于客户端程序的实现。
-
工作方式
- 协议:基于文本行的协议,能通过telnet直接操作Memcached服务存取数据。
- 应用层传输协议及报文格式见BinaryProtocolRevamped
-
异步I/O,其实现方式是基于事件的单进程和单线程的。使用libevent作为事件通知机制,多个服务器端可以协同工作,但这些服务器端之间是没有任何通信联系的,每个服务器只对自己的数据进行管理。
-
对数据的缓存不具备持久性,Memcached服务器进程重启后缓存的数据就会丢失。
Q:如何考虑容错?
- Memcached一次写缓存的流程
- 应用程序输入需要写缓存的数据;
- API将Key输入路由算法模块,路由算法根据Key和MemCached集群服务器列表得到一台服务器编号;
- 由服务器编号得到MemCached服务节点的ip地址和端口号;
- API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作。
- 在访问数据在缓存的情况下(缓存命中),读缓存流程和写缓存一样。如果读不命中,先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值计算出对应的可缓存数据的服务器结点,并把数据缓存进去。
4. Memcached缓存算法
4.1 余数Hash
Hash函数:hash(key)%num_of_servers
在不考虑服务器集群的伸缩性,余数Hash可以满足绝大多数的缓存路由需求。伸缩性会导致伸缩前后对同一个键值哈希的结果不同,本来缓存到的数组反而不命中,代价较大。
4.2 一致性Hash算法
一致性Hash环
先构造一个长度为n的整数环,根据节点名称的Hash值(其分布为[0, n-1])将缓存服务器节点放置在这个Hash环上,然后根据需要缓存的数据的Key值计算得到其Hash值(其分布也为[0, n-1]),然后在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
Example:
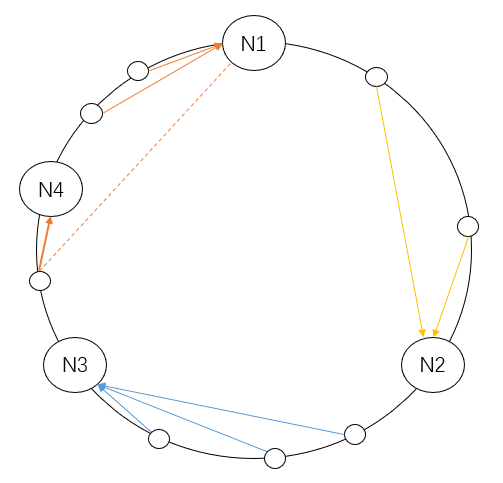
如图,添加一个节点N4,只会影响到一个key值的Hash结果,即原本映射到N1的值现在映射到N4。添加节点N4,只有处于N3到N4之间的Hash值才会受到影响,比余数Hash增加节点时代价要小得多。这也说明,集群中缓存服务器节点越多,增加节点带来的影响越小。
5. Memcached内存管理机制
Memcached利用Slab Allocation机制来分配和管理内存。
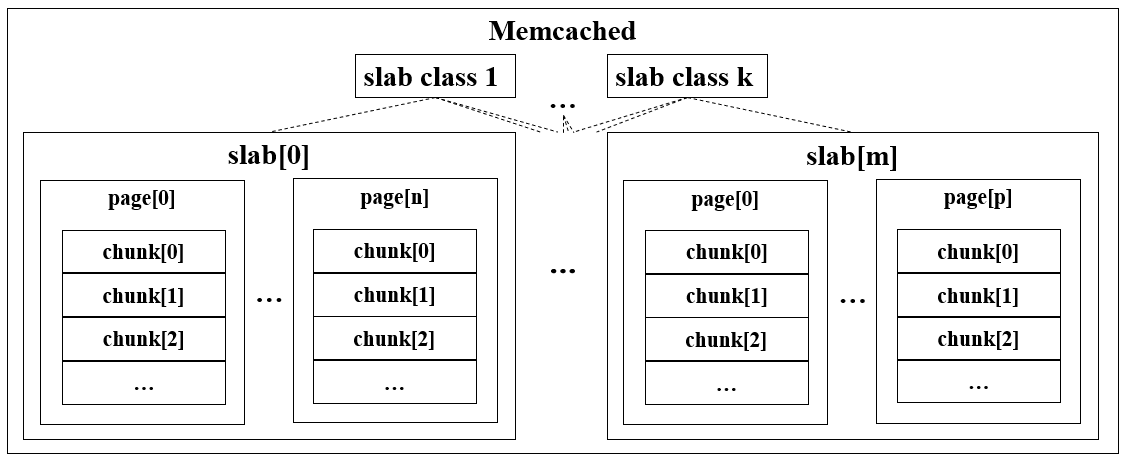
slab是memcached分配的基本单位,每个slab对应多张Page(默认大小是1M),每张Page会被划分为多个chunk(每个chunk中都保存了一个item结构体、一对key和value)。
- MemCache将内存空间分为一组slab;
- 每个slab下又有若干个page,每个page默认是1M;
- 每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的;
- 有相同大小的chunk的slab被组织在一起,称为slab_class。
分配由需缓存的value的大小决定,value总会被存放到与chunk大小最接近的一个slab中。如果缓存满了,会通过最近最少使用替换策略(LRU)替换出相应的冷数据。注意MemCache的LRU算法不是针对全局的,是针对slab的。当没有可用Page时,memcached开始对slab执行LRU算法删除冷数据。
- memcached服务启动时,通过“ -f ” 选项指定一个增长因子(或叫增长系数),它能控制内存组(slab)之间的大小差异。在应用中使用Memcached时,通常可以不重新设置这个参数,使用默认值1.25进行部署。
- memcached服务启动时,通过“-M” 参数来禁止LRU替换策略,这样当Memcached在内存耗尽时,会返回一个报错信息。